
In Kubernetes einfach mit Rancher: Storage – der Kubernetes einfach mit rancher Serie – wird es um die Inbetriebnahme eines glusterFS-Heketi Clusters und allem anderen benötigten Einstellungen gehen.
Kleines Update zwischendurch
Mittlerweile würde ich von dieser Variante – auch für eine Lab/test Umgebung – Abstand nehmen. Ich habe in den letzten Monaten die Entwicklung der kubernetes-heketi Lösung betrachtet. Updates etc. kommen selten. Ich glaube die Community für diese Lösung ist relativ klein.
Ok, irgendwelche Alternativen?
Ja Die habe ich. Longhorn von rancher labs und OpenEBS von MayaData.
Beide Lösungen lassen sich super simple über Helm installieren. Longhorn bietet sogar eine eigene Oberfläche, über die automatische Backups – auf ein S3 kompatibles System – eingerichtet werden können.
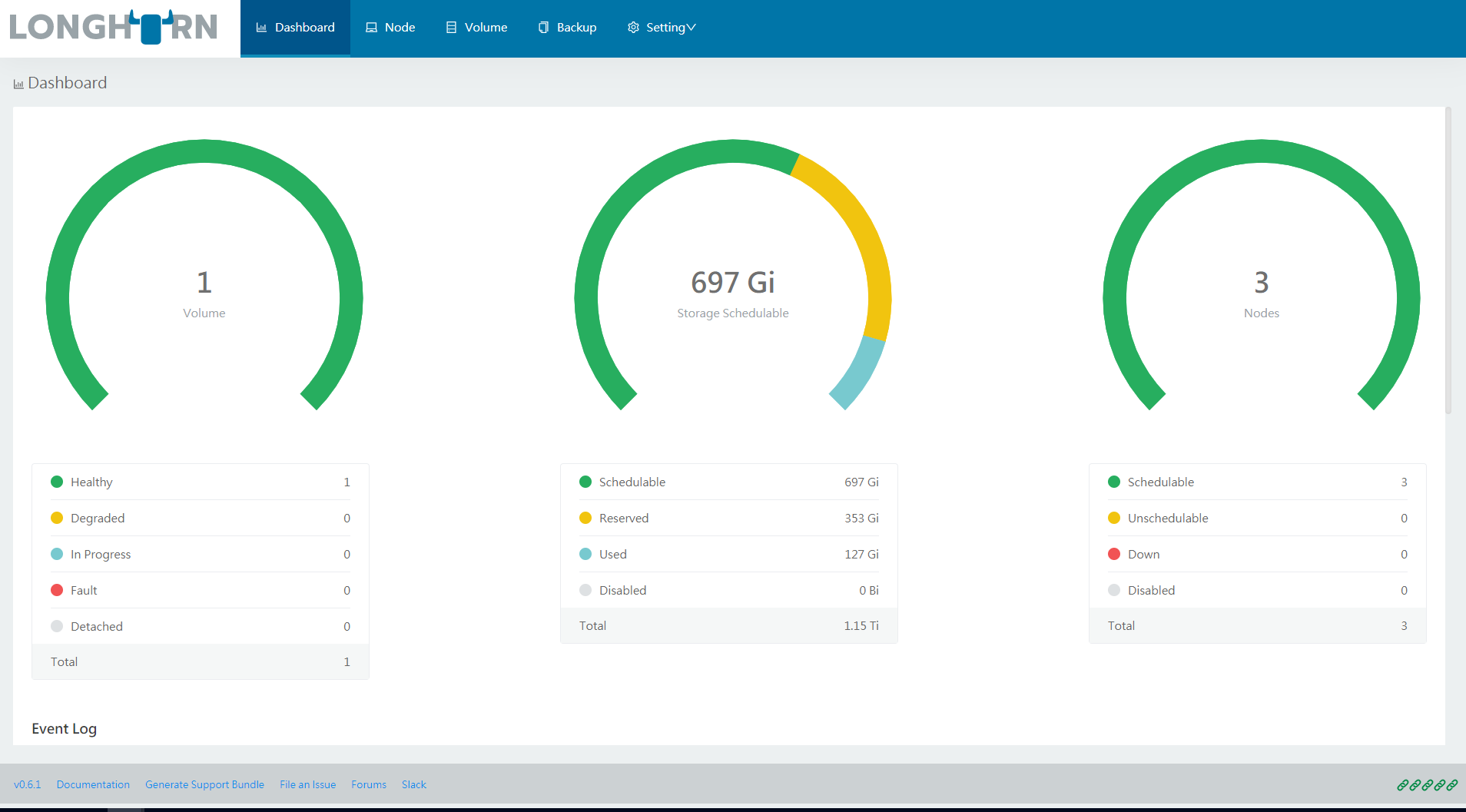
Aktuell – September 2019 – gibt es kein stable Release, mit anderen Worten es ist noch Beta. Für eine Lab Umgebung vollkommen ok, bei einer Produktiv-Umgebung würde ich daher eine Erwachsene-Lösung empfehlen. Hier kommt OpenEBS ins Spiel.
MayaData bietet zu ihrem Open Source Produkt OpenEBS auch eine Enterprise Version mit dem benötigten Support und Partnernetzwerk an. Ein Partner z.B. ist Rancher.
Für die Rancher Integration haben die Jungs bereits eine kleine Anleitung erstellt und bei einem Rancher master class Video teilgenommen.
Ich überlege noch, ob ich eigene Artikel für die Inbetriebnahme von Longhorn und OpenEBS erstelle. Aber jetzt mal weiter mit dem Kubernetes einfach mit Rancher: Storage Artikel.
Wozu brauchen wir das?
Wir möchten einen Blog auf unserem Kubernetes Cluster betreiben. So ein Blog braucht persistenten Speicher, um diesen gewährleisten zu können, muss nun etwas gemacht werden.
In dem Stateless,Statefull Artikel nennen wir als Beispiel AWS, Azure und GCE als möglichen Speicher-Anbieter. Evtl. hat man nicht die Möglichkeiten einen dieser Cloud-Dienste zu verwenden. Obendrein vertraut man den Big-Playern nicht und möchte selber für seine Dateien verantwortlich sein.
Vielleicht möchte auch jemand lernen wie so etwas funktioniert und im Alleingang selber implementiert werden kann.
Genau für diesen Jemand ist Kubernetes einfach mit Rancher: Storage gedacht. Wir werden unseren eigenen PVC mit dynamischer Provisionierung aufbauen.
Was brauchen wir dafür?
Damit wir überhaupt gluster in Betrieb nehmen können, müssen wir eine gewissen Vorarbeit auf den Servern leisten, womit wir schon beim Thema wären: Was brauchen wir eigentlich? Hier mal eine kleine Liste.
- Einen Kubernetes Cluster, Nodes
- Datenspeicher
- TCP Ports für die Kommunikation zwischen den Nodes
- Ein bisschen Linux-Verständnis
… und eine Briese gesunden Menschenverstand.
Vorarbeiten für Heketi-GlusterFS Cluster
Damit wir einen Heketi-GlusterFS Cluster einrichten können, müssen wir auf unseren Servern Anpassungen vornehmen.
Die Nodes brauchen weitere Firewall-Ports, Kernel-Module, den Gluster Client und Loop Back Devices.
Die Firewall Ports
Für den Cluster Betrieb und die Kommunikation zwischen den Nodes, müssen wir auf einpaar Ports durch die Firewall durchlassen.
ufw allow 2222/tcp
ufw allow 24007:24008/tcp
ufw allow 49152:49251/tcpDie Kernel-Module
Per modprobe schalten wir die Module dm_snapshot, dm_mirror und dm_thin_pool auf unseren Nodes aktiv.
sudo -i
echo -e "\ndm_snapshot\ndm_mirror\ndm_thin_pool" >> /etc/modules
modprobe dm_snapshot && modprobe dm_mirror && modprobe dm_thin_pool
exitGluster Client Installieren
Natürlich müssen wir auch den glusterfs-client installieren. Nun müssen wir ein neues Repository zu apt hinzufügen. Außerdem installieren wir – per apt – den Client auf allen Nodes.
sudo add-apt-repository ppa:gluster/glusterfs-3.10
sudo apt update
sudo apt install glusterfs-client -yLoop Devices Erstellen
Wer bereits leere Partitionen hat und diese Verwenden möchte, kann diesen Abschnitt überspringen.
Wir führen die folgenden Aktion auf allen Nodes aus.
Zuerst erstellen wir eine leere 25GB große Datei. Für dieses Beispiel habe ich eine eigene Verzeichnisstruktur erstellt.
mkdir /var/local/loops
dd if=/dev/zero of=/var/local/loops/glusterimage bs=1M count=25600Nun haben wir einen Fake-Datenträger für unseren Loop-Back, wodurch wir diesen Datenträger einem Loop Device zuweisen können.
losetup /dev/loop0 /var/local/loops/glusterimageIm nächsten schritt erstellen wir eine neue Datei um die Funktionalität nach einem Neustart zu gewährleisten.
touch /etc/systemd/system/gluster_loopback.service
nano /etc/systemd/system/gluster_loopback.serviceNach der Erstellung der Dateien müssen wir folgenden Inhalt in die Datei kopieren.
[Unit]
Description=Activate loop device
DefaultDependencies=false
After=systemd-udev-settle.service
Before=lvm2-activation-early.service
Wants=systemd-udev-settle.service
[Service]
Type=oneshot
ExecStart=/sbin/losetup /dev/loop0 /var/local/loops/glusterimage
[Install]
WantedBy=local-fs.targetIm letzten Schritt aktivieren wir per systemctl unsere Direktiven.
systemctl enable /etc/systemd/system/gluster_loopback.serviceDie Vorbereitungen für die Inbetriebnahme sind nun abgeschlossen.
GlusterFS mit Heketi Initialisieren
In Kubernetes einfach mit Rancher: Storage gehen wir auf die Inbetriebnahme per GlusterFS und Heketi ein, von diesem Ziel sind wir nicht mehr weit entfernt.
Die Installationsanleitungen auf gluster.org bringen uns für unser Vorhaben wenig. Für unser Vorhaben werden wir gluster-kubernetes verwenden.
Topologie
Bevor wir mit der Installation loslegen, müssen wir jedenfalls eine Toplogie-Datei – JSON Format – erstellen.
Für mein Initiales Beispiel für meinen Cluster würde die Topologie wie folgt aussehen.
{
"clusters": [
{
"nodes": [
{
"node": {
"hostnames": {
"manage": ["akube01"],
"storage": ["10.0.0.1 "]
},
"zone": 1
},
"devices": ["/dev/loop0"]
},
{
"node": {
"hostnames": {
"manage": ["akube02"],
"storage": ["10.0.0.2"]
},
"zone": 1
},
"devices": ["/dev/loop0"]
},
{
"node": {
"hostnames": {
"manage": ["akube03"],
"storage": ["10.0.0.3"]
},
"zone": 1
},
"devices": ["/dev/loop0"]
}
]
}
]
}Der devices Abscnitt ist ein Array, hier können pro Node mehrere Devices angegeben werden. Leere Partitionen, weitere Loop-Devices etc.
gluster-kubernetes installieren
Als nächstes müssen wir den Source Code von Github herunterladen. unsere Topologie in einer Datei speichern und ein bash script starten mit dem gluster inkl. heketi bereitgestellt wird.
Für dieses Task habe ich meinen Master – die Rancher Umgebung – verwendet. Im besagtem Script wird kubectl aufgerufen, daher sollte zum einen kubectl installiert sein und zum anderen die aktuelle Kubernetes Konfiguration auf dem Server abgelegt sein.
Kubectl lässt sich über apt installieren und die Konfiguration kann über die Rancher UI heruntergeladen werden.
Ich lege die Config immer in einem Subfolder unterhalb von .kube ab (root). In diesem Beispiel ~/.kube/akube/config
Nun erstellen wir einen Clone von dem gluster-kubernetes repository.
git clone git@github.com:gluster/gluster-kubernetes.gitAnschließend navigieren wir in das deploy Verzeichnis unterhalb von gluster-kubernetes.
cd gluster-kubernetes/deployAuf dieses Verzeichnis-Ebene erstellen wir nun eine neue Datei mit dem Namen „akube-gluster.json“ und kopieren unsere Topologie in diese Datei.
touch akube-gluster.json
nano akube-gluster.json
Nun müssen wir das gk-deploy script ausführen.
./gk-deploy -gy akube-gluster.jsonDadurch werden die pods erstellt und gestartet. Nachdem das Script durchgelaufen ist können wir für unseren neuen PVC eine Storage Class anlegen. Das kann in der Rancher Oberfläche oder per YAML eingerichtet werden.
Wir haben fertig!
Nunja, wir sind fast fertig mit der Serie. Als nächstes folgt ein Beitrag bzgl. der Inbetriebnahme von einem Ghost Blog. Einmal stelle ich die Inbetriebnahme über helm – mit eigenem DB pod – und zum anderen als deployment – mit SQLite, also ohne eigene externe RBDMS – vor. Dann haben wir fertig.
Was erwartet uns nach dieser Serie? Ich werde versuchen alle bereits existierenden Beiträge aktuell zu halten. Zum anderen wende ich mich dem FaaS – Functions As A Service – Thema zu. Hierzu werde ich meine Erfahrungen teilen. Themen finden sich eigentlich ziemlich schnell.
[…] Version 0.60). Ich hatte Longhorn mittlerweile einige male erwähnt – unter anderem in dem Kubernetes einfach mit Rancher: Storage […]
[…] Version 0.60). Ich hatte Longhorn mittlerweile einige male erwähnt – unter anderem in dem Kubernetes einfach mit Rancher: Storage […]